
Edge Computing is reshaping how organizations process data by moving compute resources closer to the data source, enabling faster insights, greater resilience, and more responsive applications across factory floors, retail spaces, and remote sites. When teams compare this approach with cloud computing, they must weigh regulatory requirements and the practical realities of deployment at scale. This introductory guide outlines where each model excels, presents a straightforward decision framework, and points toward a balanced path that blends on-site processing with centralized services. By understanding the strengths and trade-offs of these architectures, organizations can design more reliable systems, optimize performance, and control costs. This approach supports resilient operations by enabling targeted processing where it matters most while preserving the benefits of centralized analytics.
From another angle, the concept is often described as localized processing, edge processing, or perimeter computing—terms that emphasize bringing intelligence closer to data creation points. Rather than routing every signal to a central data center, organizations leverage local compute, micro data centers, and fog-like architectures to reduce latency and boost responsiveness. This approach complements cloud-based systems, enabling a hybrid cloud strategy that combines on-site analytics with scalable cloud services. By focusing on data locality, interoperability, and governance, teams can design architectures that balance immediacy with enterprise-scale insights. In practice, many deployments blend edge devices handling real-time tasks with cloud platforms handling long-term storage and advanced analytics.
Edge Computing for Latency Optimization and Data Sovereignty: Real-Time Insights at the Edge
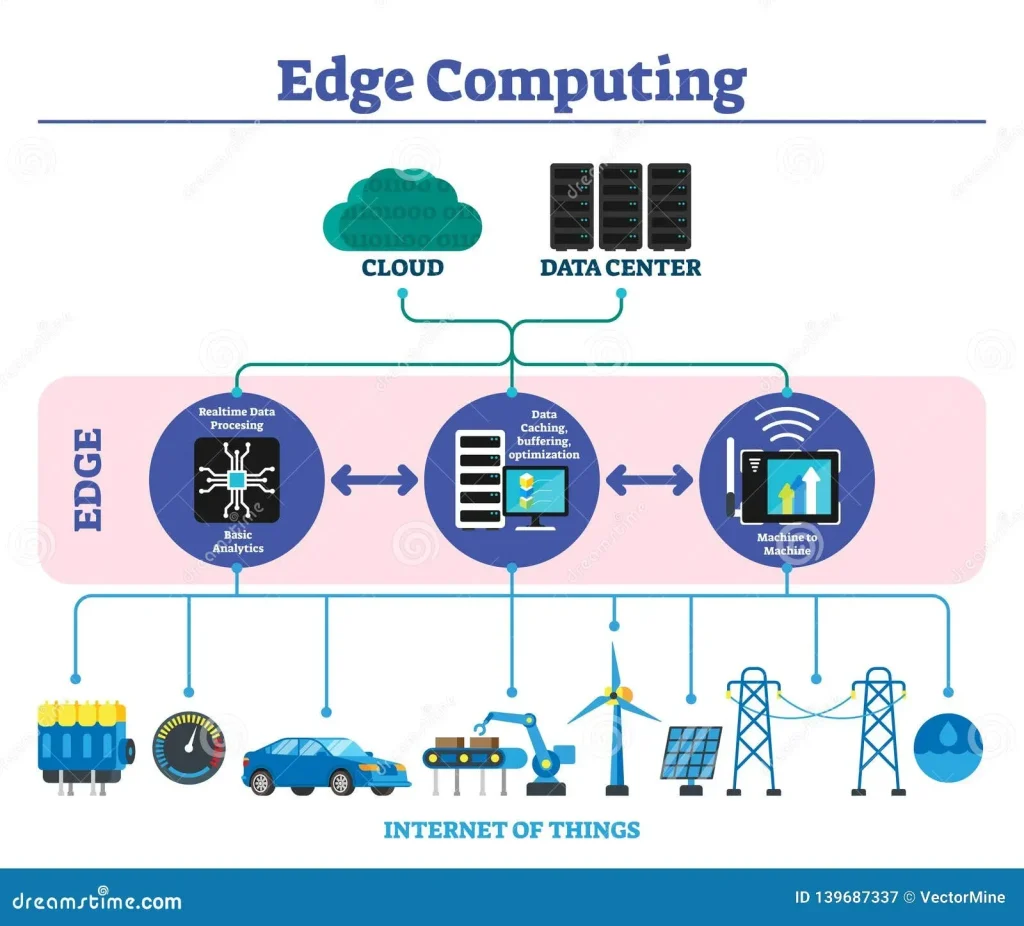
Edge computing brings processing closer to where data is produced, enabling real-time analytics on devices and local servers. By reducing round-trip times and limiting upstream bandwidth, organizations gain faster decision-making for applications like industrial automation, autonomous systems, and smart cities. This latency optimization improves responsiveness and user experience while helping maintain data locality when regulatory boundaries require that sensitive data stay within a geographic region.
In practice, edge deployments complement centralized data platforms. Local processing can filter, analyze, and act on critical signals before data is sent for long-term storage or deeper analytics in the cloud. This approach supports a hybrid cloud strategy where edge and cloud work together: edge handles time-sensitive tasks; cloud provides scalability, governance, and advanced analytics. Emphasize data sovereignty and privacy by aligning edge data handling with regulatory requirements, while still enabling centralized insights where appropriate.
Cloud Computing and the Hybrid Cloud Strategy: Scalable Centralization Meets Edge-Driven Performance
Cloud computing provides elastic provisioning, global reach, and access to AI services and big data analytics. It excels at scale, provisioning speed, and uniform policy enforcement across regions. For workloads that require heavy computation or broad data integration, centralizing processing in the cloud simplifies governance and optimization of resources.
A practical hybrid cloud strategy orchestrates workloads between edge and cloud, routing latency-sensitive tasks to edge while streaming non-time-critical data to the cloud for archival and large-scale analytics. This model balances latency considerations with data governance, data sovereignty, security, and cost control. By designing data flows and interoperability carefully, organizations can avoid silos and maintain a cohesive policy framework across both environments.
Frequently Asked Questions
How does edge computing impact latency optimization versus cloud computing?
Edge computing processes data near the source, reducing round-trip time and enabling real-time analytics, which drives latency optimization for time-sensitive applications. In contrast, cloud computing centralizes processing in remote data centers, offering scalable analytics and easier management for non-time-sensitive workloads. A hybrid cloud strategy can route latency-critical tasks to the edge while leveraging cloud computing for long-term storage and heavy analytics.
How do data sovereignty considerations and a hybrid cloud strategy influence the choice between edge computing and cloud computing?
Data sovereignty requirements often favor local data processing at the edge to keep data within geographic boundaries and comply with residency rules. Cloud computing provides centralized governance, security posture management, and broad analytics capabilities for global operations. A hybrid cloud strategy blends both, processing sensitive data at the edge while using cloud computing for scalable analytics and policy enforcement across regions.
| Topic | Key Points |
|---|---|
| Edge Computing vs Cloud Computing | Edge: processes data near the source to reduce latency, lower bandwidth needs, and enable real-time analytics. Cloud: centralizes processing/storage, offers scalability, centralized governance, and access to a broad ecosystem of services. |
| When Edge Shines | Latency optimization; bandwidth management; data sovereignty and privacy; regulatory compliance; effective for time-sensitive or locally constrained environments. |
| Use Cases Across Industries | Industrial IoT sensors with anomaly detection and local control; retail edge devices for camera analytics; healthcare patient monitoring with low latency; edge complements cloud rather than replacing it. |
| Cloud Computing Strengths | Centralized provisioning and orchestration; elastic scale; access to AI/analytics and storage; global governance and policy consistency; ideal for data science, archival storage, disaster recovery. |
| Hybrid Cloud Strategy | A hybrid approach routes time-sensitive tasks to the edge while streaming non-time-critical data to the cloud for long-term storage and heavy analytics; requires careful data flow, security, and interoperability design. |
| Key Decision Factors | Latency, bandwidth, data residency and regulatory constraints, security and governance, operational complexity, cost, interoperability, and risk of vendor lock-in. |
| Practical Decision Framework | Map workloads by latency/data volume/regulatory needs; profile the network; define data flows; start with a pilot; establish governance spanning both edge and cloud. |
| Security & Compliance | Edge security requires device hardening, secure boot, encryption, robust access controls; continuous monitoring and regular updates; manage compliance across edge and cloud. |
| Implementation Tips | Start with data locality; invest in edge management platforms; plan for scalability; align IT and OT teams; pursue vendor-neutral, modular architectures. |
Summary
HTML table provided above summarizes the core distinctions and guidance from the base content on Edge Computing and Cloud Computing.

